
韓國科學技術院(KAIST)人工智能研究所的三位研究人員開發(fā)了一種名為"鏈式變焦"(Chain-of-Zoom)的創(chuàng)新框架。該技術能夠利用現(xiàn)有的超分辨率模型生成極致放大的圖像,且無需進行模型重新訓練。
在這項發(fā)表于《arXiv》預印本平臺的研究中,Bryan Sangwoo Kim、Jeongsol Kim和Jong Chul Ye三位研究者將圖像放大過程分解為多個步驟,并在每個步驟中應用現(xiàn)有超分辨率模型進行漸進式畫質(zhì)提升,最終實現(xiàn)分辨率的多級優(yōu)化。
研究團隊首先指出,當前主流的圖像分辨率提升框架多采用插值或回歸方法進行放大,這往往會導致圖像模糊。為解決這一問題,他們開創(chuàng)性地采用了分步變焦技術——通過前后步驟的迭代優(yōu)化來實現(xiàn)畫質(zhì)提升。
由于該技術采用了多級處理鏈來提升分辨率,研究人員將其命名為"鏈式變焦"(CoZ)框架。
在每一級處理中,該框架都會調(diào)用現(xiàn)有的超分辨率(SR)模型啟動優(yōu)化流程。與此同時,視覺語言模型(VLM)會生成描述性提示詞,輔助SR模型完成圖像生成過程。最終輸出的就是原始圖像某個局部區(qū)域的放大版本。
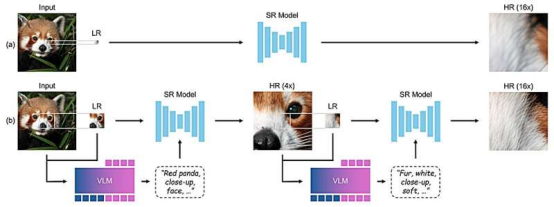
該框架隨后會循環(huán)這一過程,在視覺語言模型生成的有效提示詞輔助下,不斷優(yōu)化放大圖像的分辨率,直至生成最終版本。為確保視覺語言模型生成的提示詞切實有效,研究團隊應用了強化學習技術進行優(yōu)化。測試結果表明,該框架生成的圖像質(zhì)量超越了標準基準測試的水平。
研究人員特別強調(diào),該框架無需重新訓練就能提升圖像質(zhì)量,這使得它具有更好的通用性。但同時他們也提醒使用者必須謹慎對待該技術的應用場景——這些放大后的圖像并非真實畫面,而是人工智能生成的產(chǎn)物。
舉例來說,如果用它來放大銀行搶劫案中逃逸車輛的牌照,系統(tǒng)可能會顯示出非常清晰的字母和數(shù)字,但這些內(nèi)容可能與真實車牌并不相符。
精選文章:
閱讀空間:當代書店設計中商業(yè)與社區(qū)的平衡藝術
大作洗眼 | 2025 DIELINE最佳包裝、普京“懸空別墅”…全面性設計!
觀點:社交媒體圍攻正在扼殺創(chuàng)意產(chǎn)業(yè)嗎?