
近期,基于文本的圖像生成模型已能根據(jù)自然語(yǔ)言描述自動(dòng)創(chuàng)建高分辨率、高質(zhì)量的圖像。然而,當(dāng)輸入"創(chuàng)意"這類抽象文本時(shí),即便是Stable Diffusion這樣的典型模型,其生成真正具有創(chuàng)造力圖像的能力仍顯不足。
韓國(guó)科學(xué)技術(shù)院(KAIST)的研究人員開(kāi)發(fā)了一項(xiàng)新技術(shù),無(wú)需額外訓(xùn)練即可提升Stable Diffusion等文本生成圖像模型的創(chuàng)造力,使AI能夠設(shè)計(jì)出突破常規(guī)的創(chuàng)意椅子造型。
KAIST金在哲人工智能研究生院的崔宰碩教授團(tuán)隊(duì)與NAVER AI實(shí)驗(yàn)室合作,開(kāi)發(fā)了這項(xiàng)無(wú)需額外訓(xùn)練即可增強(qiáng)AI生成模型創(chuàng)造力的技術(shù)。該研究已發(fā)布于arXiv預(yù)印本服務(wù)器論文鏈接,代碼開(kāi)源在GitHub。
崔教授團(tuán)隊(duì)通過(guò)放大文本生成圖像模型內(nèi)部特征圖的技術(shù)來(lái)增強(qiáng)創(chuàng)意生成能力,同時(shí)發(fā)現(xiàn)模型淺層模塊對(duì)創(chuàng)意生成起關(guān)鍵作用。他們證實(shí):將特征圖轉(zhuǎn)換至頻域后,若放大高頻區(qū)域數(shù)值會(huì)導(dǎo)致噪點(diǎn)或色彩碎片化。
因此,研究團(tuán)隊(duì)證明放大淺層模塊的低頻區(qū)域能有效提升創(chuàng)意生成效果。
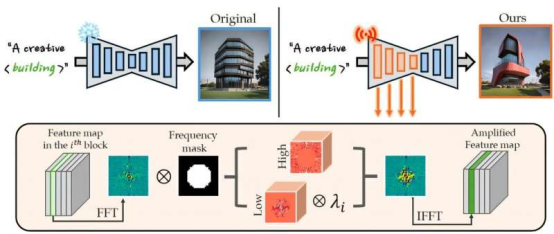
研究團(tuán)隊(duì)將原創(chuàng)性和實(shí)用性定義為創(chuàng)造力的兩大核心要素,提出了一種能自動(dòng)選擇生成模型各模塊最佳放大值的算法。通過(guò)該算法,適當(dāng)放大預(yù)訓(xùn)練Stable Diffusion模型的內(nèi)部特征圖,無(wú)需額外分類數(shù)據(jù)或訓(xùn)練即可增強(qiáng)創(chuàng)意生成能力。
研究團(tuán)隊(duì)通過(guò)多維度指標(biāo)定量證明,其算法生成的圖像比現(xiàn)有模型更具新穎性,同時(shí)未顯著犧牲實(shí)用性。特別是在SDXL-Turbo模型(為提升Stable Diffusion XL生成速度開(kāi)發(fā)的版本)中,該技術(shù)有效緩解了模式崩潰問(wèn)題,顯著提升了圖像多樣性。用戶研究表明,相比現(xiàn)有方法,人類評(píng)估者也認(rèn)為其新穎性與實(shí)用性的平衡度有顯著改善。

論文共同第一作者、KAIST博士生韓知妍和權(quán)多熙表示:"這是首個(gè)無(wú)需重新訓(xùn)練或微調(diào)即可增強(qiáng)生成模型創(chuàng)意能力的方法。我們證明通過(guò)特征圖操控,能激發(fā)已訓(xùn)練AI生成模型中潛在的創(chuàng)造力。"
她們補(bǔ)充道:"這項(xiàng)研究使得僅用文本就能從現(xiàn)有訓(xùn)練模型中輕松生成創(chuàng)意圖像。預(yù)計(jì)將為創(chuàng)意產(chǎn)品設(shè)計(jì)等領(lǐng)域帶來(lái)新靈感,推動(dòng)AI模型在創(chuàng)意生態(tài)中的實(shí)用化應(yīng)用。"
該研究由KAIST金在哲人工智能研究生院的博士生韓知妍和權(quán)多熙共同完成,已于6月16日在計(jì)算機(jī)視覺(jué)與模式識(shí)別國(guó)際會(huì)議(CVPR)上發(fā)表。
精選文章:
巴黎大皇宮經(jīng)過(guò)沙蒂永建筑事務(wù)所四年整修后重新開(kāi)放
優(yōu)衣庫(kù)和Labubu聯(lián)名,設(shè)計(jì)好萌!
數(shù)據(jù)驅(qū)動(dòng)設(shè)計(jì):為什么每個(gè)用戶體驗(yàn)決策都需要數(shù)字支撐