
谷歌近日為其Gemini 2.5 AI模型推出了一項(xiàng)新功能,用戶可以通過(guò)自然語(yǔ)言指令直接分析并突出顯示圖像內(nèi)容。
這項(xiàng)"對(duì)話式圖像分割"技術(shù)超越了傳統(tǒng)的圖像識(shí)別方式——傳統(tǒng)方法通常只能通過(guò)固定類別(如"狗"、"汽車"或"椅子")來(lái)識(shí)別物體。現(xiàn)在,Gemini能夠理解更復(fù)雜的語(yǔ)言描述,并將其應(yīng)用于圖像的特定部分。該模型可以處理關(guān)系型查詢(如"打傘的人")、邏輯指令(如"所有沒(méi)有坐著的人"),甚至是沒(méi)有明確視覺(jué)輪廓的抽象概念(如"雜物"或"損壞")。得益于內(nèi)置的文本識(shí)別功能,Gemini還能識(shí)別需要讀取屏幕上文字的圖像元素,例如展示柜中的"開(kāi)心果果仁蜜餅"。該功能支持多語(yǔ)言指令,并能根據(jù)需要提供其他語(yǔ)言的物體標(biāo)簽,比如法語(yǔ)。
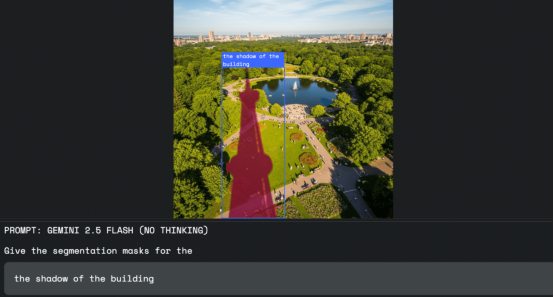
圖片來(lái)源:谷歌
實(shí)際應(yīng)用場(chǎng)景
據(jù)谷歌介紹,這項(xiàng)技術(shù)可應(yīng)用于多個(gè)領(lǐng)域。例如在圖像編輯中,設(shè)計(jì)師不再需要使用鼠標(biāo)或選擇工具,只需說(shuō)出他們想要選擇的內(nèi)容,比如"選擇建筑物的陰影"。
在工作場(chǎng)所安全方面,Gemini可以掃描照片或視頻中的違規(guī)行為,例如"所有在建筑工地未戴安全帽的人員"。
該功能在保險(xiǎn)行業(yè)也很有用:理賠員可以發(fā)出"突出顯示所有遭受風(fēng)暴損壞的房屋"等指令,自動(dòng)標(biāo)記航拍圖像中受損的建筑物,與手動(dòng)檢查每處房產(chǎn)相比節(jié)省了大量時(shí)間。
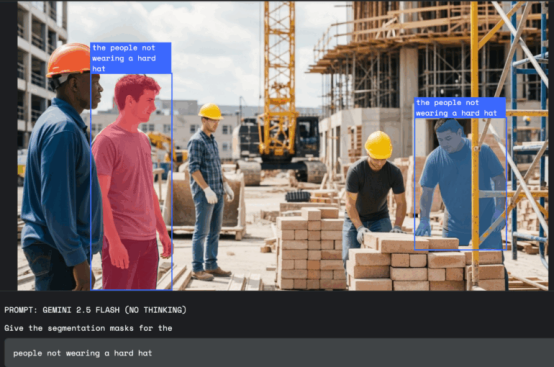
圖片來(lái)源:谷歌
無(wú)需特殊模型
開(kāi)發(fā)者可以通過(guò)Gemini API訪問(wèn)該功能。所有請(qǐng)求都由具備此功能的Gemini模型直接處理。
返回的結(jié)果采用JSON格式,包括所選圖像區(qū)域的坐標(biāo)(box_2d)、像素掩碼(mask)和描述性標(biāo)簽(label)。
為了獲得最佳效果,谷歌建議使用gemini-2.5-flash模型,并將"thinkingBudget"參數(shù)設(shè)置為零以觸發(fā)即時(shí)響應(yīng)。
用戶可通過(guò)Google AI Studio或Python Colab進(jìn)行初步測(cè)試。
精選文章:
月租1999元的小米青年公寓火了!大廠如何從 “搶人”轉(zhuǎn)向“留人”?
從大廠到獨(dú)立:為何越來(lái)越多的創(chuàng)意人選擇單飛